
lnadekhdikcpjfnlhnbingbkhkfkddkl


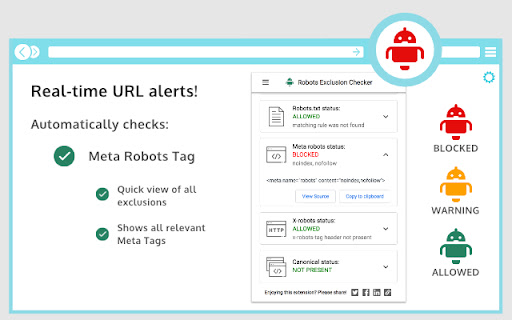


Checks robots.txt, meta robots, x-robots-tag with URL alerts. Canonical warnings, HTTP header info. An SEO extension, robots tester. Robots Exclusion Checker is designed to visually indicate whether any robots exclusions are preventing your page from being crawled or indexed by Search Engines. ## The extension reports on 6 elements: 1. Robots.txt 2. Meta Robots tag 3. A.I. Bots 4. X-robots-tag 5. Rel=Canonical 6. UGC, Sponsored and Nofollow attribute values If a URL you are visiting is being affected by an "Allow” or “Disallow” within robots.txt, the extension will show you the specific rule within the extension, making it easy to copy or visit the live robots.txt. You will also be shown the full robots.txt with the specific rule highlighted (if applicable). Cool eh! Any Robots Meta tags that direct robots to “index", “noindex", “follow" or “nofollow" will flag the appropriate Red, Amber or Green icons. Directives that won’t affect Search Engine indexation, such as “nosnippet” or “noodp” will be shown but won’t be factored into the alerts. The extension makes it easy to view all directives, along with showing you any HTML meta robots tags in full that appear in the source code. Checks whether a website's robots.txt file blocks A.I. companies from accessing its content. It monitors 14 bots across 6 companies - OpenAI, Anthropic, Google, Perplexity, Meta, and Apple, covering three types of access: training data collection, search indexing, and real-time browsing. If any bot exclusions are detected, an "AI" label will appear over the Robots Exclusion Checker icon in your browser. This feature can be deactivated within settings if preferred. Spotting any robots directives in the HTTP header has been a bit of a pain in the past but no longer with this extension. Any specific exclusions will be made very visible, as well as the full HTTP Header - with the specific exclusions highlighted too! Although the canonical tag doesn’t directly impact indexation, it can still impact how your URLs behave within SERPS (Search Engine Results Pages). If the page you are viewing is Allowed to bots but a Canonical mismatch has been detected (the current URL is different to the Canonical URL) then the extension will flag an Amber icon. Canonical information is collected on every page from within the HTML and HTTP header response. - UGC, Sponsored and Nofollow A new addition to the extension gives you the option to highlight any visible links that use a "nofollow", "ugc" or "sponsored" rel attribute value. You can control which links are highlighted and set your preferred colour for each. I’d you’d prefer this is disabled, you can switch off entirely. Within settings, you can choose one of the following user-agents to simulate what each Search Engine has access to: This tool will be useful for anyone working in Search Engine Optimisation (SEO) or digital marketing, as it gives a clear visual indication if the page is being blocked by robots.txt (many existing extensions don’t flag this). Crawl or indexation issues have a direct bearing on how well your website performs in organic results, so this extension should be part of your SEO developer toolkit for Google Chrome. An alternative to some of the common robots.txt testers available online. This extension is useful for: - Faceted navigation review and optimisation (useful to see the robot control behind complex / stacked facets) - Detecting crawl or indexation issues - General SEO review and auditing within your browser ## Avoid the need for multiple SEO Extensions Within the realm of robots and indexation, there is no better extension available. In fact, by installing Robots Exclusion Checker you will avoid having to run multiple extensions within Chrome that will slow down its functionality. 1.0.3: Various bug fixes, including better handling of URLs with encoded characters. Robots.txt expansion feature to allow the viewing of extra-long rules. Now JavaScript history.pushState() compatible. 1.0.4: Various upgrades. Canonical tag detection added (HTML and HTTP Header) with Amber icon alerts. Robots.txt is now shown in full, with the appropriate rule highlighted. X-robots-tag now highlighted within full HTTP header information. Various UX improvements, such as "Copy to Clipboard” and “View Source” links. Social share icons added. 1.0.5: Forces a background HTTP header call when the extension detects a URL change but no new HTTP header info - mainly for sites heavily dependant on JavaScript. 1.0.6: Fixed an issue with the hash part of the URL when doing a canonical check. 1.0.7: Forces a background body response call in addition to HTTP headers, to ensure a non-cached view of the URL for JavaScript heavy sites. 1.0.8: Fixed an error that occurred when multiple references to the same user-agent were detected within robots.txt file. 1.0.9: Fixed an issue with the canonical mismatch alert. 1.1.0: Various UI updates, including a JavaScript alert when the extension detects a URL change with no new HTTP request. 1.1.3: Added UGC, Sponsored and Nofollow link highlighting. 1.1.4: Switched off nofollow link highlighting by default on new installs and fixed a bug related to HTTP header canonical mismatches. 1.1.6: Extension now flags 404 errors in Red. 1.1.7: Not sending cookies when making a background request to fetch a page that was navigated to with pushstate. 1.1.8: Improvements to the handling of relative vs absolute canonical URLs and unencoded URL messaging. 1.2.0.11: Updating to Google's new manifest V3 and fixing small bugs. 1.2.0.12: Added a Spanish language version and made improvements to existing translations. Linking to new website https://www.checkrobots.com 1.2.0.13: Fixed pushState navigation data extraction, resolved inconsistent icon display, and added security protections to prevent logout issues with enterprise websites. 1.3.0: Introduced A.I. bot checking to monitor robots.txt exclusion rules for 14 bots across 6 companies including OpenAI, Anthropic, Google, Perplexity, Meta and Apple, with training, search indexing and real-time browsing bots tracked. New site exclusion feature lets you skip checking for specific domains. Fixes for SPA/back-forward navigation, x-robots-tag case sensitivity for Bingbot and Yahoo and improved allow/disallow rule precedence. Redesigned settings page with collapsible sections.

NoFollow
Outline nofollow links, detect nofollow and noindex meta tags on webpages. Features website filtering and custom CSS outline styles. :: Features ★ supports NOFOLLOW, UGC, and SPONSORED attribute values ★ supports search engine specific robot meta tags ★ disable or enable extension for defined websites v6.0.0 - switched to extension manifest V3 - added export and import - added keyboard shortcuts - removed "Remember minimised state" setting - now it always remembers minimised state across browser restarts - misc code improvements v5.3.3 - fixed visual issues in extension options for high pixel density screens v5.3.2 - trying a fix for errors on Mac OS v5.3.0 - ignore certain errors in logger - added CSP for better security v5.2.2 - fixed issue where extension would not mark links with image nested more than one level deep v5.2.0 - support for UGC and SPONSORED attribute values (there is no way to visually distinguish it from NOFOLLOW value at this time) - replaced facebook and twitter share links on options page v5.1.0 - improved the way injected script communicates with background script - fix: improved error logging v5.0.0 - new: added outline for links without nofollow attribute ("DoFollow" links) - new: added outline for external links - new: added "D" button next to each style input so you can easily restore default style value - new: inject content scripts to already opened browser tabs on extension start, this should improve user experience on extension install and update - change: updated minimum requirements to Chrome v39 - change: updated default outline styles (this will be noticed only by new users) - change: merged content scripts into one script, should use less resources now - change: made sure that extension doesn't try to load itself into pages from web store to avoid "no permission" errors - change: improved error logging - change: removed Google+ icon and updated Facebook and Twitter icons ===> Full changelog on the website

Seerobots
SeeRobots conveniently displays the meta robots information of the website you are viewing - For more info visit www.seerobots.com SeeRobots will conveniently show you the information meta robots tag in the head section of the website your are viewing at that moment. Depending on this information colors in the browserbar will change. 1. If the SeeRobots field is all green it means that this page has "index, follow" as robots attributes. 2. If the SeeRobots field is all red it means that this page has "noindex, nofollow" as robots attributes. 3. If the SeeRobots field is green on the left and red on the right it means that this page has "index, nofollow" as robots attributes. 4. If the SeeRobots field is red on the left and green on the right it means that this page has "noindex, follow" as robots attributes.

NoIndex,NoFollow Meta Tag Checker
By default, Googlebot will index a page and follow links to it. You can use a special HTML tag to tell robots not to index the content of a page, and/or not scan it for links to follow. For example: In the majority of cases this is only used on development or staging sites and not used on live websites. This extension generates a notification if a robots meta tag is found with either "noindex" or "nofollow" in the contents.

View Rendered Source
View source is dead. See how the browser renders a page, not just what the server sends. A lightweight Chrome Extension that shows you how the browser has constructed (rendered) a page's original HTML into a functioning DOM, including modifications made by JavaScript. An essential tool for web developers using JavaScript frameworks like Angular, ReactJS and Vue.js, and for SEOs to understand how search engines see your pages, especially considering Google's dynamic serving workaround. Differences between raw and rendered versions are highlighted line-by-line showing how JavaScript has modified a page at render time. * Raw: The source code sent from the server to the browser before the DOM is rendered. The same as you'll see with traditional 'View Source' in the browser (after minor formatting tweaks) * Rendered: The rendered page after the source has been interpreted into a DOM, including any modifications made by Javascript * Difference: The difference between the rendered source and the raw source. Differences occur when JavaScript has modified the DOM. Adaptive website? If you serve different source code to mobile devices, emulate this easily with a mobile user-agent checkbox. Dynamic serving for Google? (More info: https://developers.google.com/search/docs/guides/dynamic-rendering) Using Google's dynamic rendering workaround designed for Javascript-heavy sites? Just request the raw source as Googlebot and ensure perfect technical SEO. Works with GatsbyJS and Prerender. DM the developer: https://twitter.com/ItsHogg